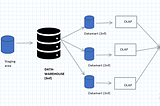
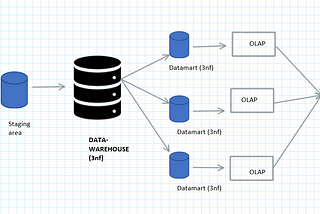
PinnedSarit MaitraHybrid Data Architecture & Migration ChallengesHybrid data-warehouse capitalizes the strengths of both solutions·11 min read·Aug 26, 2021----
PinnedSarit MaitraReturn, Risk Measurement & Portfolio Optimization TechniqueCapital allocation with Convex Optimization, Kelly’s Criterion & Markowitz Efficient Frontier·13 min read·Jul 23, 2021----
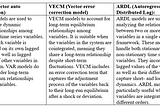
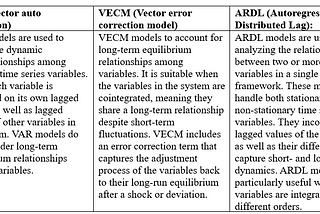
Sarit MaitraThe importance and application of Vector Error Correction Model (VECM)The auto regressive category has three distinct models; let is clear our understanding of them using the table below.·10 min read·Feb 13, 2024--1--1
Sarit MaitraBest of Momentum Strategy to Find Consistent Trend Using RSIHow momentum trading strategy can yield sustainable return·7 min read·Aug 16, 2021--2--2
Sarit MaitraMathematical Optimization Model Using Stochastic Time-SeriesMean-variance & Convex portfolio optimization model·11 min read·Aug 13, 2021----
Sarit MaitraTake Time-Series a Level-Up with Walk-Forward ValidationOptimize time-series with Walk-Forward Validation·10 min read·Aug 2, 2021--1--1
Sarit MaitraBack-Testing Mean Reversion Trading Strategy with Threshold Value-Energy SeriesTrend following mean reversion with look-back interval·9 min read·Jul 10, 2021----
Sarit MaitraSolve Skewed Binary Class Distribution with Neural NetworkDifficult task of solving Imbalance Class distribution·8 min read·Jul 4, 2021----
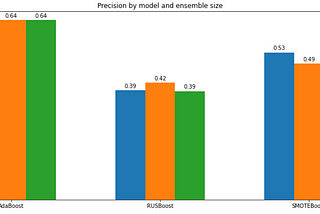
Sarit MaitraSolve Imbalanced Class with Boosting AlgorithmsAdaBoost, RUSBoost & SMOTEBoost to improve the classification performance·11 min read·Jun 30, 2021--1--1
Sarit MaitraImportance of Mathews Correlation Coefficient & Cohen’s Kappa for Imbalanced ClassesWhich accuracy metrics to use for imbalanced class use case?·11 min read·Jun 27, 2021--1--1